BugsDoneQuick: Days 3-4 recap: Let there be light

July 6th through 13th was a busy week for me. In a previous post I recapped the events for my BugsDoneQuick event up to the end of day two, after I had gone through my first 6-hour stream, excited for the days to come. Little did I realize the challenge was only just beginning; it hadn't yet dawned on me that I'm only at the third day out of 8, less than half-way through.
This post is part of a series:
- Part 1: covers days 1 and 2; with JavaScript and more JavaScript.
- Part 2: covers days 3 and 4; with Python and some more KDE; this is the article you are currently reading.
- Part 3: will cover days 5, 6, and 7, and focus on LibreOffice—stay tuned!
- Part 4: will summarize everything and cover day 8—stay tuned!
Note that you can always also watch the recordings from the BugsDoneQuick streams—if you would rather watch me write open-source code, rather than read about me having written open-source code.
(P.S. Apologies for the delay with which this article came out; I had a very busy August to deal with 😅)
Day 3: Zarr - Recording
Other than Element, to which I contributed on day 1, I had only one other project recommended by a friend for BugsDoneQuick: the Zarr ecosystem. And, as it happens, it was my choice for a project for day 3.
Zarr is a relatively new file format used for storing N-dimensional arrays of data, such as matrices or tensors. It's meant to be a simpler, easier to implement, maintain, and use alternative to tensor storage solutions like HDFS or Apache Arrow. On top of that, it supports chunking/sharding stored data into multiple files, accessing data over HTTP or S3, and organizing and annotating stored data with metadata. (Guess which ones of those had issues related to them for me to work on.)
But, at the start of the stream, I knew next to nothing about Zarr. And since Zarr-Python was the first library I was going to contribute to, I decided it would be best to spend the first ~50 minutes of the stream familiarizing myself with Zarr's features.
In addition, I had the realization that one of the target audiences for my streams would be the maintainers of the projects I contribute to, since they could analyze the footage to look for parts of the codebase that trip contributors up, or parts of the documentation that are unclear. So, I posted a message in Zarr's Zulip channel announcing my intention to livestream, and got one of the main developers to join the stream! His help in getting me up to speed with Zarr was invaluable, and in return, I hope I have inspired some improvements to the documentation 😇 😁
Issue 5: Group attributes not shared between different instances of the same group object
In Zarr, groups are used for organizing a dataset into a hierarchical structure of arrays and sub-groups. In filesystem terms, groups are like folders while arrays are like files—and in fact, in the Zarr version 3, groups are basically just folders with an extra JSON file for metadata.
As it happens, it's not very hard to get multiple references to the same group in Zarr's Python version:
import zarr
store = zarr.storage.MemoryStore()
reference_a = zarr.create_group(store, path="/")
reference_b = zarr.open_group(store, path="/")However, each reference to the group has its own copy of the metadata of the group, and there is no way to re-synchronize the metadata captured by the reference, other than recreating the whole reference:
reference_a.attrs["a"] = 1
reference_b.attrs["a"] # KeyError
reference_c = zarr.open_group(store, path="/")
reference_c.attrs["a"] # 1Here, I thought I could modify open_group to return the same Group object every time it is called. That involved making all the parameters for opening a group—the store and the path—hashable, so they could be used in an impromptu memoization hash table.
However, this idea quickly ran afoul of open_group's other parameters that control the Group object being returned. In particular the zarr_format parameter (which switches between Zarr v2 and v3) was a problem, since it could be autodetected. Adding it to the cache key was an option, but there were 3 or 4 places that all needed to precisely coordinate how they create new groups for all if it to work—and that was enough to convince me there is a better way. (Especially when I realized that arrays require similar treatment but have a lot more parameters, and that one might still need a way to re-read the attributes of a group that gets modified by a different process, the whole solution fell apart.)
Therefore, I switched to an alternative solution: adding a refresh_attributes method that updates the attributes of the group when called.
To implement that, I inspected the code responsible for initially reading the metadata (in the Group class's constructor) as well as the code responsible for saving the attrs dictionary of the group when it is modified (in an update_attributes function called by a special dictionary-like object returned by the attrs property). Then, I combined the two to get a function that reads the metadata and updates the attrs dictionary of the group.
From there, it was a matter of polish. Looking through the codebase, I had spotted an option called "cache_attrs" left over from Zarr v2, that was not implemented after the migration to Zarr v3. I decided it'd be nice if accessing attrs would call refresh_attributes automatically when that option was set, so I implemented that. Then, I also went around and did the same changes for Array-related classes. Some documentation and further polish later, right as the 2-hour mark hit, everything was complete and wrapped in a pull request.
With that PR in place, you can now disable attribute caching, and attributes synchronization between instances "just works":
reference_a = zarr.create_group(store, path="/", cache_attrs=False)
reference_b = zarr.open_group(store, path="/", cache_attrs=False)
reference_a.attrs["a"] = 1
reference_b.attrs["a"] # 1(Granted, that PR led to a long discussion about the merits of stateful and stateless objects and is yet to be merged.)
Issue 6: Negative zeroes not stored on disk
The next issue for the day was more of an edge case, a bug, and not an architectural problem. Zarr-python v2 had been able to store arrays with negative zeros; Zarr-python v3 was no longer storing chunks of the array composed entirely of negative zeros. The bug already had some discussion on it and the maintainers and bug reporter already had not just a reproduction project, but also a few cases in which the issue doesn't happen.
Given that, it was very clear where the issue happens: in the code responsible for determining whether a chunk should be persisted to disk depending on whether the chunk is all-zeroes or not. So, I decided to I could really go for speed this time around.
I was quick to reproduce the issue locally, locate the exact lines of code I need to change, (get lost investigating the v2 code, only to realize it never actually triggers), look at Numpy's documentation for a function to use when comparing arrays of positive and negative zeroes, and finally rush a code implementation and unit test.
It was my fastest solve yet: a scant 43 minutes for a bug.
However, the hastiness showed in the pull request I submitted. I had left debug prints, didn't minimize my unit tests, and even managed to break tests for object arrays. So, I'm not sure I can actually count the 43 minutes as my personal best time or not. I suppose that might count as an Any% personal best?
Oh well. Live and learn 😅
In any case, I got back to this issue after the week was over, and made sure to implement things right, testing whether the new implementation supports subnormal floating-point numbers and NaNs correctly.
Issue 7: Race condition in creating sharded arrays
The last issue of day 3 that I dared take on was a race condition when creating an array with shards (files stored on disk) larger than the individual chunks (pieces) of the array (thus having multiple chunks for every file), which manifested itself as an odd checksum mismatch error whenever Zarr was allowed to use multiple threads for storing data.
As usual, I started by reproducing the issue locally. The example code from the issue itself managed to reproduce the issue instantly, so I spent some time minimizing the example, trying to figure out the minimum size of the array at which I would reliably get the issue to occur again—and experimentation revealed that maximizing the number of chunks per shard is one of the most reliable ways to reproduce the issue. At that point, I also looked at the stored that, and realized that the issue is not in the checksum, but in the fact that we end up with only one chunk stored in the whole shard - because all the chunks get written at the same time, and the shard-writing code is not thread-safe.
At that point, I went on a goose chase, trying to figure out who ends up calling the shard-writing code multiple times for the same shard. Inasmuch as I tried to get an idea by doing educated changes to the code in hopes of it randomly starting to work, I couldn't get anything out. But, once I started back at the beginning, in the array creation function, I finally spotted it: array creation iterated the input array in parallel by chunks and not by shards, thus causing all the writes to the same shard to happen through different chunks.
Correcting that was relatively easy, just switching a few functions to support iterating over shards and not chunks. Some tests later, I polished it up and submitted it as a pull request to the project—after 1 hour and 53 minutes of chasing the race condition around.
That roughly concluded the third day. I was a bit tired throughout the whole day, and I'm afraid that reflected in the quality of the code submissions I made. At the same time, Zarr developers had high expectations of correctness and robustness of any new code merged in—not a great fit for speeding through issues with no concern for anything but making it work. I am very well impressed with the Zarr community, however; he welcome I got was really warm, and even if only one of my three submissions has been merged this far (after heavy corrections), the dedication to consistency and detail is really good to see.
Day 4: Gwenview - Recording
I already touched on some KDE software when I was preparing for BugsDoneQuick, and after a lengthy late-night discussion with Tim Krief about Kdenlive issues, I decided I'd rather do something with KDE again.
...Especially when I couldn't compile LibreOffice fast enough, so I had to leave it for day 5 😂
For that end, I picked Gwenview—KDE's image viewer application.
Issue 8: Annotated images get upscaled with display scaling
The first issue I took on was something I thought would be rather simple: a display scaling issue concerning image annotations. Somehow, on fractional display scaling (say, with all fonts and sizes set to 125% of their normal size), the image annotation function in Gwenview—which allows for drawing on images, without pulling up a more advanced image editor—would upscale the image when saving it.
Unfortunately for me, the annotator is a separate package, outside of KDE's repositories. Gwenview uses kImageAnnotator, which was developed as part of the ksnip screenshot tool, and is not affiliated with KDE. As it happens, the upscaling behavior happens entirely in kImageAnnotator - and most of the time fixing this issue was getting a local version of kImageAnnotator built and linked with Gwenview.
In the end, the issue was in the function responsible for rendering the image with the annotations to a new image—it was picking a larger image size than the original when display scaling was on. I tried fixing it on Gwenview's side by changing the DPI of the image, but that led to kImageAnnotator rounding up the image size to the nearest multiple of two, so instead, I opted to make a change in kImageAnnotator that makes it render to the unscaled, original image size... then spent another hour, confirming that doing that didn't break anything in ksnip.
In the end, a bit short of the two-hour mark, I submitted a pull request to kImageAnnotator and mentioned it in the original issue.
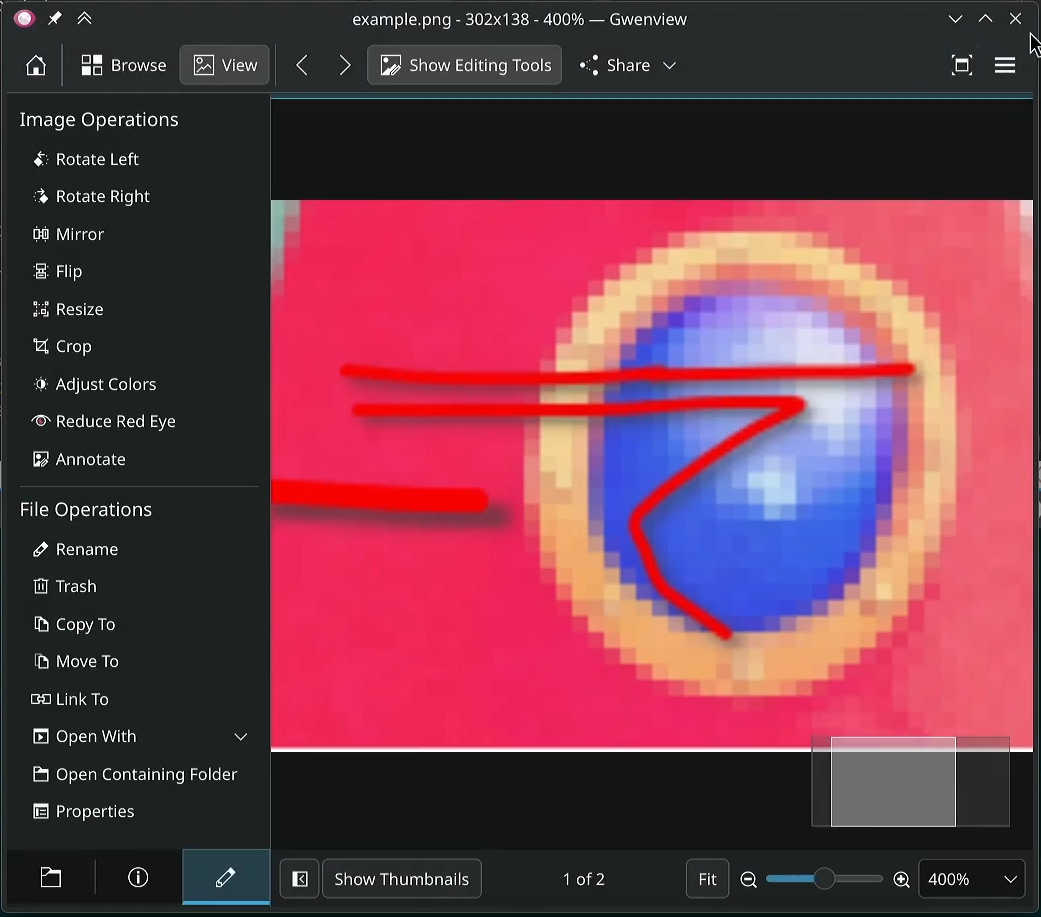
Issue 9: Reload externally-modified images automatically
For the next issue, I two issues to pick from:
- BUG 505972 reported that images that are modified on disk don't get automatically reloaded in Gwenview.
- Meanwhile, BUG 505635 reported that images that are deleted on disk get automatically closed in Gwenview.
Clearly, something was off—and a choice had to be made. Either Gwenview should always display the latest version of the image, closing it if it goes missing, or Gwenview should always display the initially-opened version of the image, reloading it if instructed to do so. Given my experience with Okular (KDE's PDF document viewer), which automatically reloads things that get modified, I figured that this is the more useful behavior of the two, so I set out to fix the first bug, 505972, and ignored the second one.
Given that the second issue hinted at Gwenview already having some component that observes certain changes to the currently open image, I started by looking for it. I found that in the code responsible for the thumbnails view—if it detects that the currently-opened image was removed from the list of thumbnails, it would automatically select the next image from the list. From there, I noticed something curious—the thumbnail view also got updated when an image is modified!
From there, it was a matter of figuring how to pass the signal along, so that the image would get reloaded if it's the currently selected one. That took a total of 5 carefully-placed lines, and after 53 minutes, I submitted my first proper merge request to Gwenview.
Issue 10: Show media buttons for .gif files
Emboldened by my success with Gwenview so far, I figured I could take on a slightly more complicated feature request, adding media controls to .gif files, so they could be started/stopped/played/paused and even advanced frame-by-frame.
At first, I figured it would be a rather simple issue, as I though I would be able to reuse the library for playing videos, MPV, to show GIF files too. However, just switching around the implementation used for viewing gif files from the specialized animated image viewer to the video viewer resulted in the video not scaling correctly (it filled the whole window as a movie, rather than trying to fit at 100% scale like an image) and not looping correctly—in addition to displaying volume controls which are useless for .gif images. While I could adapt the scaling code of the image viewer to the video viewer and figure a way around looping, I figured it would be simpler to port the code for the media controls to the animated image viewer.
"Simpler", in this case, being an euphemism for "2 hours and 13 minutes of dealing with object-oriented interfaces". The main trouble was that Gwenview used a nice, clean object-oriented interface with the State pattern for dealing with documents that are loaded at first, before suddenly become animated images, static images, or videos. Then, that State pattern was coupled to an Adapter pattern (adapting between a single State implementation and a single viewer implementation), for extra measure. In the end, that meant that any single piece of data, such as the number of frames an animation has, had to go through around 3-4 layers of indirection, and required changing as many files to pass it along to where it's needed. (Then changing all those files again, when I realized I didn't name the newly-added methods correctly.)

Conclusion
On the second two days, I was finally starting to realize what streaming for 6 hours a day was going to take—a lot of sweat, even for just a week. I hadn't quite found a bug that might best me yet, and at two hours per bugfix, it felt like a breeze, even if I was gradually getting more tired. Of course, all of that was going to change as soon as I went ahead to try LibreOffice, on the 5th day—where I finally got something to stump me for 4 hours straight, and had to go for a rematch. But more about that—next time!
As for viewership; getting a Zarr developer to watch as I worked my way with Zarr was amazing; and that is a strategy I copied for later. My Gwenview stream was one of my less watched streams, but that's okay; I was taking my time and preparing for the C++ challenges ahead. Still, if anyone watched it, or if anyone benefited from what I did then: I'm most glad to have been an indirect part of your journey like that. 😊
This is my 22th post of #100DaysToOffload. I'm.. er, on the clock to post 2 articles a week or lose the challenge now! 😬 😂
Browse more articles?
← BugsDoneQuick: Days 1-2 Articles tagged BugsDoneQuick (5/5) →|
← You can now browse my site by tags! Articles tagged technology (13/16) Joining forces on Xee →
← Chasing shiny things Articles tagged 100DaysToOffload (22/40) Joining forces on Xee →
← Chasing shiny things Articles on this blog (29/47) Joining forces on Xee →